SoK: How Robust is Audio Watermarking in Generative AI models?
Abstract: Audio watermarking has been used for provenance verification of AI-generated content
from generative models. It spawns a
wealth of applications for detecting AI-generated speech, protecting the music IP, and defending against
voice cloning
attacks. Generally, audio watermarking should be robust against removal attacks that distort the signal
to evade
detection. Many audio watermarking schemes claim robustness; however, these claims are often validated
in isolation
against a limited set of attacks. There is no systematic, empirical evaluation of robustness against a
comprehensive set
of removal attacks in the audio domain. This uncertainty complicates the deployment of watermarking
schemes in practice.
In this paper, we survey and evaluate whether recent audio watermarking schemes claiming robustness can
withstand a
broad range of removal attacks. First, we propose a taxonomy for 25 audio watermarking schemes. Second,
we summarize the
audio watermark technologies and their potential vulnerabilities. Third, we conduct a large-scale,
comprehensive
measurement study to evaluate the robustness of existing watermarking schemes. To facilitate this
analysis, we develop
an evaluation framework encompassing a total of 22 types of watermark removal attacks (109 different
configurations).
Our framework covers signal-level distortions, physical-level distortions, and AI-induced distortions.
We identify 8 new
attacks that are highly effective against all watermarks and discover 11 key findings that illustrate
their fundamental
weaknesses. Our study reveals critical insights: none of the surveyed watermarking schemes is robust
enough to withstand
all tested distortions in practice. The extensive evaluation offers a holistic view of how well— or
poorly—current
watermarking schemes fare under real-world threats.
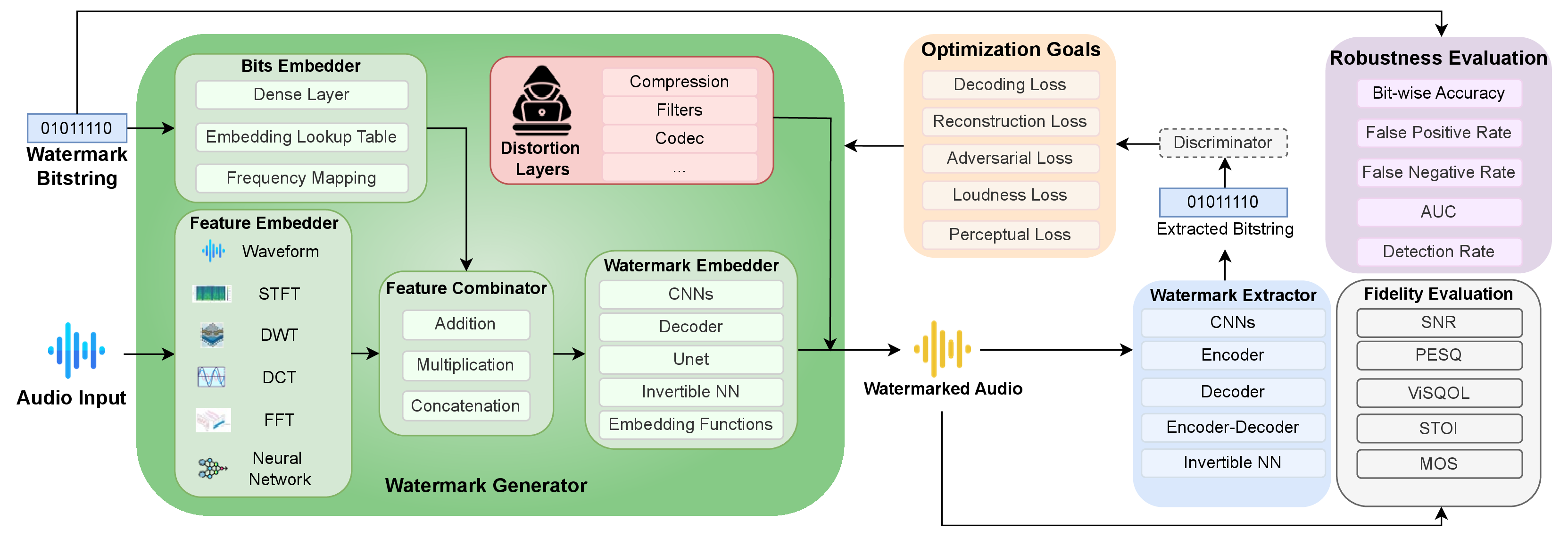
Audio Watermarking Process
The figure above illustrates the audio watermarking process. A watermark generator encodes user-provided
data (e.g., '0101110') into an audio signal, creating a watermarked audio file. A watermark detector
then extracts and decodes this data from the audio to verify its authenticity.
For the watermark robustness evaluation across three attack scenarios—AI-Induced Distortion Attacks,
Physical-Level Distortion Attacks, and Signal-Level Distortion Attacks—we present both the distorted audio
samples and their corresponding watermark Bit Recovery Accuracies (Acc.) for each watermarking technique.
Watermark accuracies exceeding 80% are highlighted in green,
while those below 80% are marked in red. Accuracy values
near 50% indicate performance comparable to random guessing.
Watermarked Audio Samples
We present audio examples illustrating different watermarking schemes, including new watermark audio samples and additional results from LibriSpeech.
Unwatermarked
Timbre
AudioSeal
WavMark
SilentCipher
LJ
Spectrograms
M4
Spectrograms
LibriSpeech
Spectrograms
FSVC
Patchwork
Norm-Space
audiowmark
RobustDNN
LJ
Spectrograms
M4
Spectrograms
LibriSpeech
Spectrograms
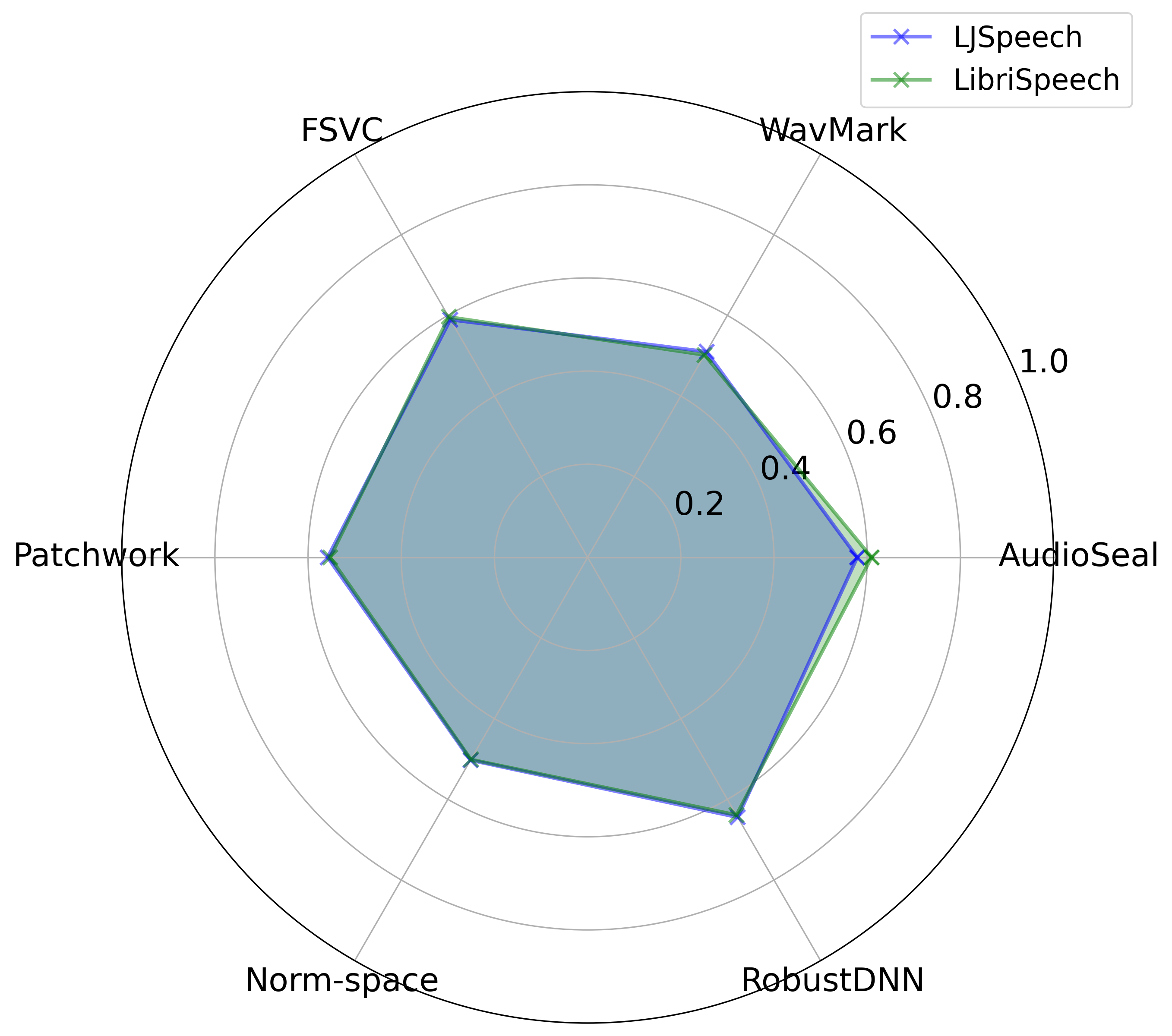
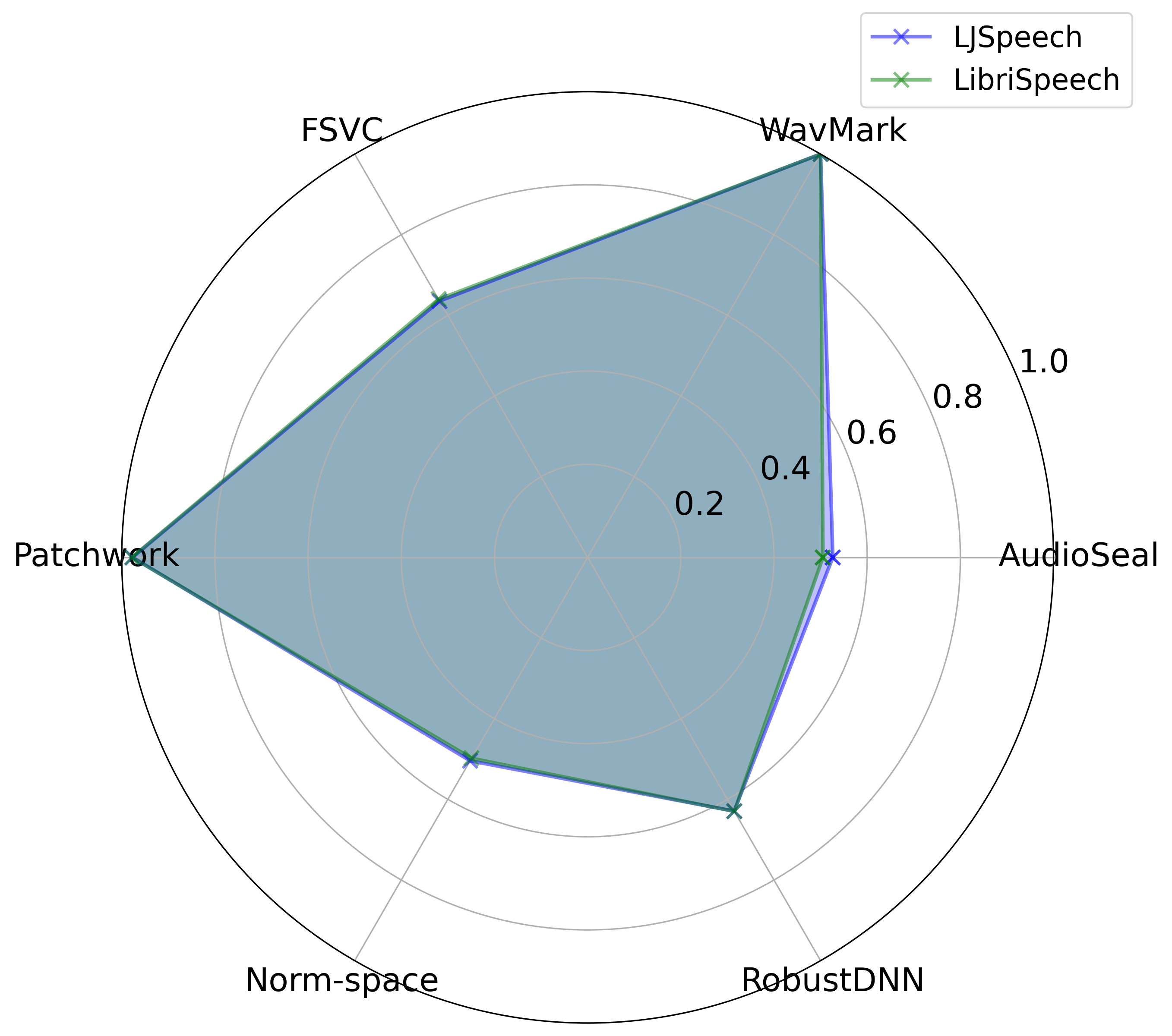
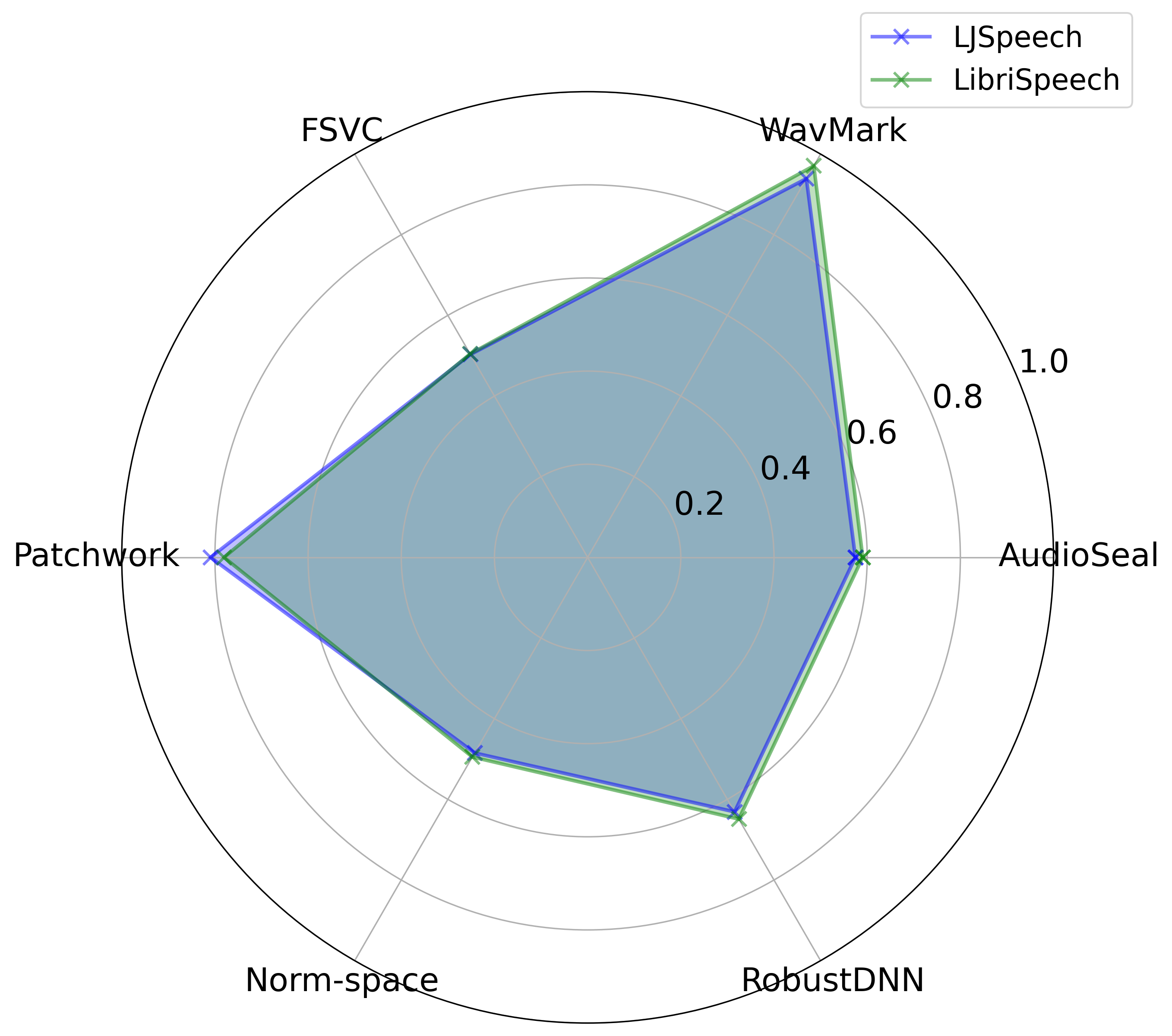
More dataset evaluation (LibriSpeech vs. LJSpeech)
We extended our robustness evaluation to the LibriSpeech dataset, focusing on three attacks:
Pitch Shift, Time Stretch, and Cutting Audio, since these three attacks are the most
relevant to our key findings 1 and 2 in our paper. Each radar chart shows watermark Acc.
(0.0 to 1.0) across six watermarking techniques. The blue polygon represents
LJSpeech, while the green polygon represents LibriSpeech.
Pitch ShiftTime StretchCutting Audio
AI-Induced Distortion Attacks
For AI-induced distortion attacks, we present results for voice conversion and Text-to-Speech (TTS) attacks
conducted on the LJ Speech dataset.
Voice Conversion
In zero-shot and few-shot scenarios, the watermarked audio samples are directly input into pre-trained Voice
Conversion Models, with the goal of removing or adding the watermark through these models. In adaptive
scenarios, the Voice Conversion Models are fine-tuned using unwatermarked audio samples, aiming to train the
models to learn how to remove or add the watermark to the audio samples.
Timbre
AudioSeal
WavMark
SilentCipher
FSVC
Patchwork
Norm-Space
audiowmark
AdaIn-VC (zero-shot)
RM WM
Acc.
65.34%
59.59%
51.26%
49.78%
57.18%
49.71%
49.86%
49.29%
ADD WM
Acc.
93.06%
49.10%
49.27%
50.30%
51.35%
49.88%
49.83%
FragmentVC (zero-shot)
RM WM
Acc.
56.28%
49.76%
50.37%
53.54%
51.35%
49.24%
50.10%
ADD WM
Acc.
58.38%
50.00%
49.99%
52.50%
51.15%
49.66%
49.81%
MediumVC (zero-shot)
RM WM
Acc.
48.52%
53.64%
49.70%
49.96%
63.66%
53.03%
50.25%
50.83%
ADD WM
Acc.
49.08%
50.90%
50.55%
52.25%
52.91%
50.55%
50.78%
YourTTS VC (zero-shot)
RM WM
Acc.
59.64%
57.50%
50.06%
49.61%
53.31%
52.26%
50.34%
50.40%
ADD WM
Acc.
62.16%
51.26%
50.05%
52.98%
51.51%
49.73%
49.90%
RVC (adaptive)
RM WM
Acc.
55.58%
49.96%
49.97%
57.88%
49.95%
50.01%
49.50%
ADD WM
Acc.
100%
54.34%
49.39%
52.48%
56.44%
50.41%
50.46%
Text-to-Speech
For the zero-shot configuration, we feed the text that aligns with the watermarked audio, and also provides
the watermarked audio as a reference to the pre-trained text-to-Speech models, to generate a sound that
seems like the watermarked audio source, without including the watermark. For the adaptive case, we
construct a watermarked dataset to finetune the TTS model to get a better audio similarity of the victim’s
sound. Then inference of the fine-tuned text-to-Speech models with different text.
Timbre
AudioSeal
WavMark
SilentCipher
FSVC
Patchwork
Norm-Space
audiowmark
Tacotron2
Griffin-Lim
Acc.
100%
49.83%
49.91%
58.50%
59.29%
50.20%
49.69%
HiFi-GAN
Acc.
91.36%
50.14%
50.06%
58.08%
50.16%
49.33%
50.45%
HiFi-GAN*
Acc.
100%
78.56%
50.22%
59.03%
63.69%
50.58%
51.49%
Fastspeech2
Griffin-Lim
Acc.
100%
49.64%
49.39%
67.39%
62.96%
50.13%
49.84%
HiFi-GAN
Acc.
92.48%
50.86%
49.80%
68.94%
54.61%
50.04%
50.55%
HiFi-GAN*
Acc.
100%
83.54%
49.45%
69.71%
65.38%
49.56%
50.33%
YourTTS (zero-shot)
Audio Sample
Acc.
54.20%
53.81%
49.18%
49.67%
54.59%
51.68%
46.80%
49.45%
Physical-Level Distortion Attacks
We re-record audio samples from the LJ Speech dataset using various equipment at different distances and
report the Bit Recovery Accuracy (Acc.) for each watermarking technique on the LJ Speech dataset.
Default: Macbook Pro 13-inch, M1, 2020, Built-in Microphone and Speaker
HyperX Mic: HyperX QuadCast USB Condenser Microphone, Macbook Pro Built-in Speaker
Logitech Spk: Macbook Pro Built-in Microphone, Logitech Z130 Speaker
Timbre
AudioSeal
WavMark
SilentCipher
FSVC
Patchwork
Norm-Space
audiowmark
RobustDNN
Close (0.5m)
Default
Acc.
100%
63.75%
97.50%
53.00%
55.00%
77.50%
52.50%
50.00%
72.34%
HyperX Mic
Acc.
100%
42.50%
98.75%
62.00%
62.50%
68.75%
47.50%
52.50%
63.01%
Logitech Spk
Acc.
100%
53.75%
100%
48.00%
60.00%
70.00%
51.25%
53.75%
72.46%
Medium (2.5m)
Default
Acc.
88.00%
48.75%
56.25%
51.50%
62.50%
67.50%
53.75%
48.75%
61.33%
Far (5m)
Default
Acc.
64.00%
55.00%
43.75%
52.00%
48.75%
63.75%
51.25%
48.75%
59.49%
Signal-Level Distortion Attacks
We directly manipulate the audio signal to attempt erasing or degrading the watermark using various
signal-level distortions. The distorted audio samples and their corresponding Bits Recovery Accuracy
(Acc.) are reported for each watermarking technique on samples from both the LJ Speech and M4Singer datasets.
The LJ audio sample is on top (colored gray), and the M4 sample is on the bottom (colored black). The LJ accuracy is
shown on the left, and the M4 accuracy is on the right.